
Attention
A mechanism used in AI models such as transformers that enables the model to selectively focus on different parts of the input sequence when making predictions.
Unlike traditional model architectures that process all input data with equal importance, models with attention assign different importance levels to different tokens (such as words or pixels). This allows the model to better understand the complete meaning of the input, especially when an accurate meaning depends on relationships between tokens that are far apart (such as between words that occur far apart in a sentence).
Attention is crucial for large language models (LLMs) so they can capture long-range dependencies and contextual relationships in the given text. It allows LLMs to handle complex and nuanced language, enabling them to generate coherent and contextually relevant output even when the input text includes nuanced references to other parts of the text.
Attention was introduced and refined in the papers Neural Machine Translation by Jointly Learning to Align and Translate (Bahdanau et al., 2014) and Effective Approaches to Attention-based Neural Machine Translation (Luong et al., 2015).
The most well-known form of attention is self-attention, in which each token gets its own attention score for every other token (each token "attends to" all other tokens), in order to determine the relative importance of each other token in that context.
Implementation details
The classic attention operation follows this general structure:
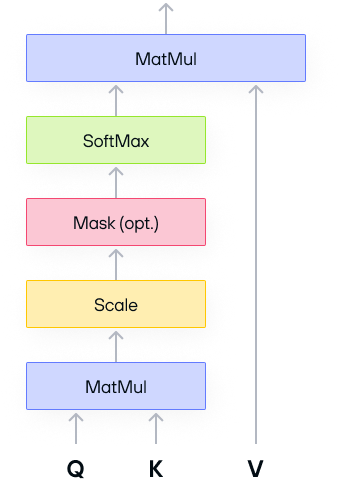
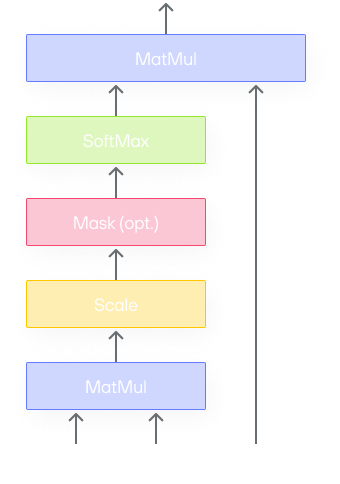
It consists of the following operations (bmm is short for batched matrix
multiplication):
bmm:Q x Transpose(K)whereQ,Kboth have shape[batchSize, numHeads, S, d]andQ x K^thas the shape[batchSize, numHeads, S, S]softmaxbmm:softmax(Q x K^t) x Vwhere V has the shape[batchSize, numHeads, S, d]
S denotes the sequence length. Depending on the model, it can be as large as
O(10^3) - O(10^4). d is the size per head in multi-head attention. It’s
usually a power of 2 like 64, 128, etc, and smaller than S.
A limitation of the classic implementation is that it materializes an
intermediate matrix of shape [batchSize, numHeads, S, S]. This introduces
O(S^2) memory allocation and traffic.
Was this page helpful?
Thank you! We'll create more content like this.
Thank you for helping us improve!