
Flash attention
Flash attention is an optimization technique to compute attention blocks in transformer models. Traditional attention requires storing large intermediate activation tensors, leading to high memory overhead that slows execution because it requires frequent memory transfers between high-bandwidth memory (HBM) and faster SRAM on the GPU.
Flash attention improves performance and reduces the memory footprint for attention layers. It reorders computations with techniques such as tiling to compute attention scores in blocks, and it keeps only small chunks of activations in the faster on-chip SRAM. This allows the model to process much longer sequences without running into memory limitations.
By improving the efficiency of attention layers, flash attention enables LLMs to handle much longer contexts, improving their ability to understand and generate complex text. It's particularly beneficial for:
- Large language models with long context windows
- Vision transformers processing high-resolution images
- Multi-modal models with large attention matrices
- Fine-tuning large models on limited GPU memory
Implementation details
Flash attention optimizes the classic attention mechanism by:
- Tiling the computation: Breaking the
Q,K, andVmatrices into smaller blocks that fit in GPU shared memory, which is much faster than global memory. - Fusing operations: Combining softmax normalization with matrix multiplication for each tile into a single kernel.
These help maximize the locality and reduce DRAM (global memory) traffic.
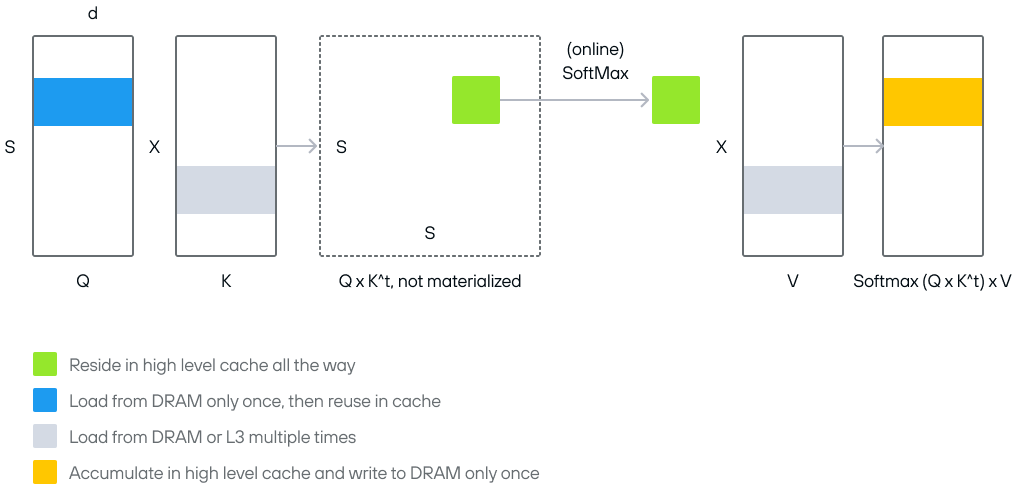
To see an implementation of
FlashAttention-2 as a fused operation, see
fused_attention.mojo on
GitHub.
Was this page helpful?
Thank you! We'll create more content like this.
Thank you for helping us improve!