
Scale your GenAI deployments
The Modular Platform provides dedicated endpoints and enterprise-grade scaling for inference workloads. This scaling logic is powered by Mammoth, a Kubernetes-native distributed AI serving tool that makes it easier to run and manage LLMs at scale using MAX as a backend for optimal model performance. It's designed to maximize hardware efficiency with minimal configuration, even when running multiple models across thousands of nodes.
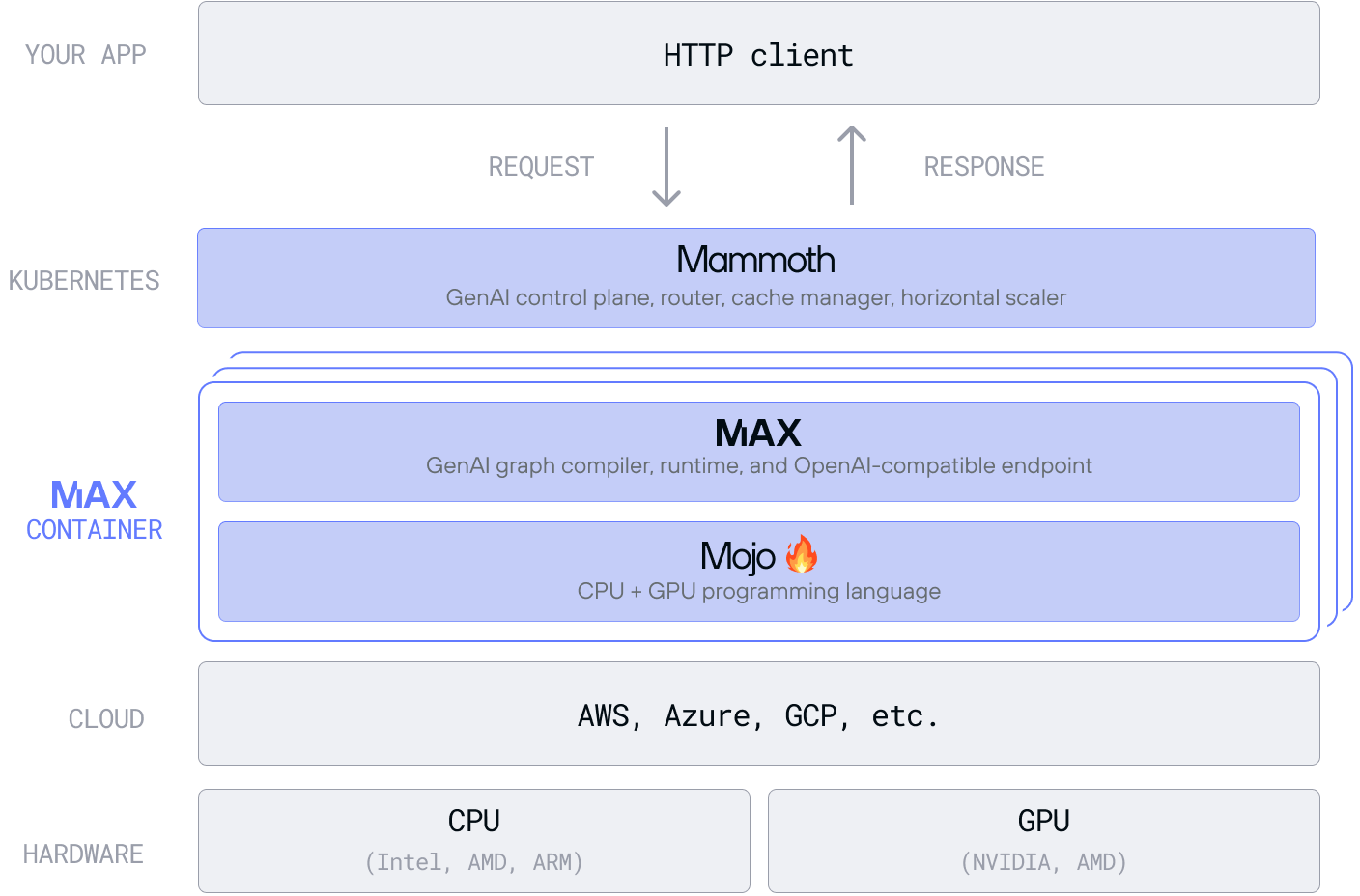
The Mammoth control plane automatically selects the best available hardware to meet performance targets when deploying a model and supports both manual and automatic scaling. Mammoth's built-in orchestrator intelligently routes traffic, taking into account hardware load, GPU memory, and caching states. You can deploy and serve multiple models simultaneously across different hardware types or versions without complex setup or duplication of infrastructure.
Access to Mammoth
If you need to serve one or more LLMs at scale with high performance and minimal operational overhead, you can do so with Modular's Dedicated Endpoint or Enterprise editions, which use Mammoth to power routing and scaling capabilities.
Mammoth makes a difference when:
- You're running inference across heterogeneous GPU clusters (NVIDIA and AMD) and need optimized, vendor-agnostic orchestration.
- You want a self-hosted, low-configuration deployment experience that works out of the box, regardless of hardware or cloud provider.
- You need to dynamically scale workloads based on traffic and resource availability, with fine-grained control over model placement and scheduling.
- You're managing fleets of models and want a unified serving layer without duplicating infrastructure.
- You're working in a Kubernetes environment and want native integration that's easy to operate and extend.
- You want to optimize total cost of ownership with cluster-level efficiency features like disaggregated inference and KV cache-aware routing.
Additionally, because Mammoth is built on the MAX framework, you can use its APIs and tools to customize and optimize every layer of the stack, from high-level orchestration down to GPU kernels written in Mojo.
How Mammoth works
Mammoth consists of a lightweight control plane, an intelligent orchestrator, and advanced optimizations such as disaggregated inference, all working together to efficiently deploy and run models across diverse hardware environments.
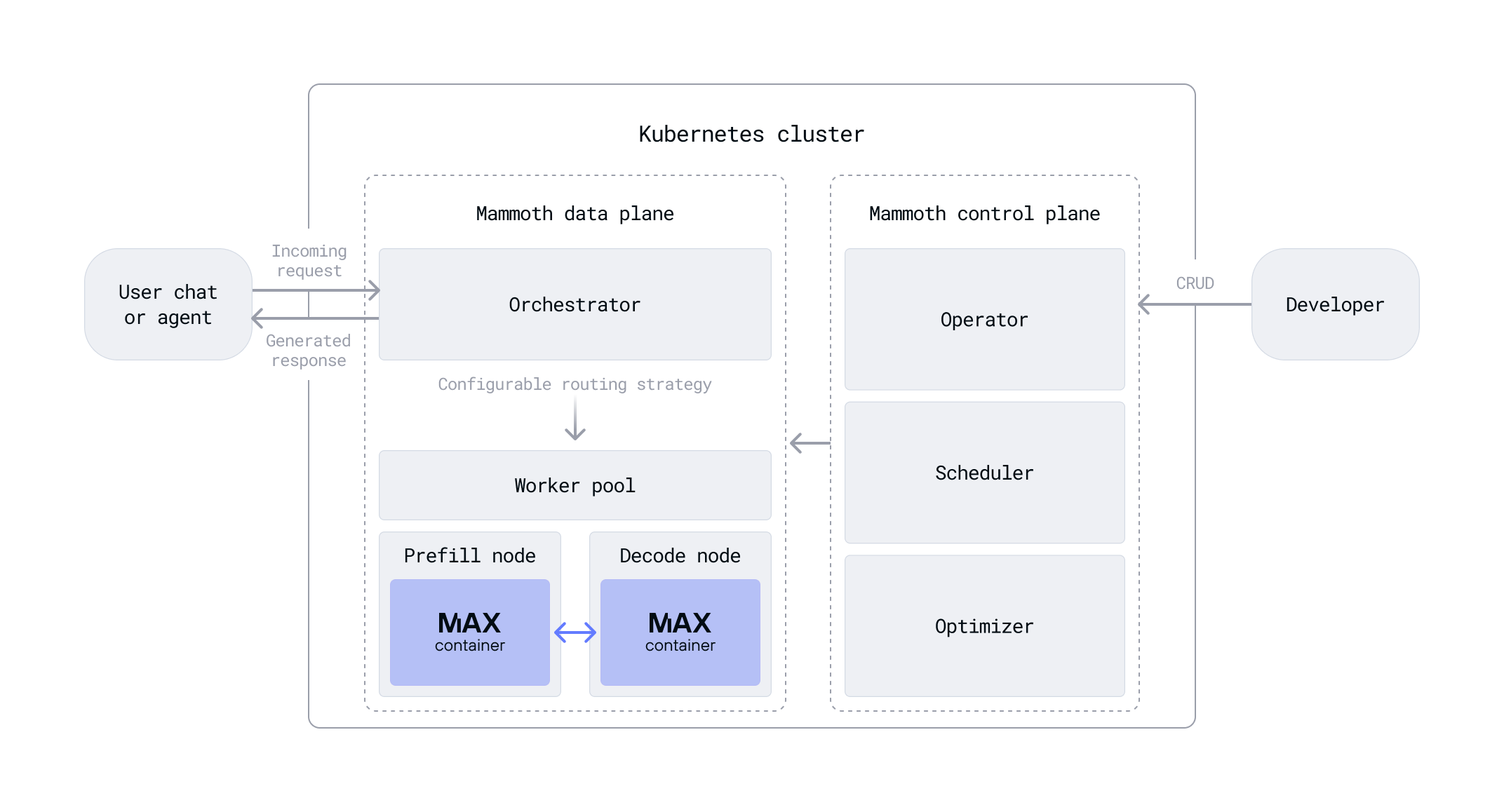
At the heart of Mammoth is its control plane, which takes care of setting up,
running, and scaling models automatically. Just provide the model ID (such as
modularai/Llama-3.1-8B-Instruct) or a path to the model on an external
storage provider like S3, and the control plane handles the rest.
You can interact with the control plane for:
- Model deployment: Launch models with a single command.
- Model management: Modify or delete deployed models.
- Multi-model orchestration: Run multiple models efficiently across shared infrastructure.
- Scaling: Adjust replicas manually or let Mammoth autoscale intelligently.
- Resource allocation: Automatically allocate GPU resources to model deployment.
The Mammoth control plane extends the Kubernetes API with custom resource definitions (CRDs) and controls those resources with an operator. When you create, update, or delete a resource, the control plane provisions infrastructure, deploys or reconfigures models, and cleans up resources as needed.
Deploy models
With Mammoth running behind the scenes, deploying models in Modular's Dedicated Endpoint and Enterprise editions is designed to be simple. You choose the model you want to serve and define your resource requirements, and Mammoth's control plane takes care of the rest. It automatically discovers available NVIDIA or AMD GPUs, schedules the workload across the cluster, and scales as needed.
Whether you're serving a single large model or multiple models at once, Mammoth handles orchestration and optimization so you can focus on your application rather than infrastructure.
Scale deployments
The control plane adjusts the deployment to the desired number of replicas and allocates resources accordingly. For production use, intelligent autoscaling is built in and configurable.
Allocate resources
You can fine-tune resource allocation for each deployment. For example, with disaggregated inference, you can assign separate GPU resources to nodes that handle prefill and decode stages independently.
Become a design partner
Mammoth is currently only available through Modular's early access program where we're actively partnering with select organizations as design partners. Design partners get early access to new features and share feedback to help shape the future of Mammoth.
Talk to an AI expert to learn more about how Mammoth can support your use case and help you scale with confidence.
Get the latest updates
Stay up to date with announcements and releases. We're moving fast over here.
Talk to an AI Expert
Connect with our product experts to explore how we can help you deploy and serve AI models with high performance, scalability, and cost-efficiency.
Was this page helpful?
Thank you! We'll create more content like this.
Thank you for helping us improve!