
Quickstart
A major component of the Modular Platform is MAX, our developer framework that abstracts away the complexity of building and serving high-performance GenAI models on a wide range of hardware, including NVIDIA and AMD GPUs.
In this quickstart, you'll create an endpoint for an open-source LLM using MAX, run an inference from a Python client, and then benchmark the endpoint.
System requirements:
Linux
WSL
GPU
If you'd rather create an endpoint with Docker, see our tutorial to benchmark MAX.
Set up your project
First, install the max CLI that you'll use to start the model endpoint.
- pixi
- uv
- pip
- conda
- If you don't have it, install
pixi:curl -fsSL https://pixi.sh/install.sh | shThen restart your terminal for the changes to take effect.
- Create a project:
pixi init quickstart \ -c https://conda.modular.com/max-nightly/ -c conda-forge \ && cd quickstart - Install the
modularconda package:- Nightly
- Stable
pixi add modularpixi add "modular==25.6" - Start the virtual environment:
pixi shell
- If you don't have it, install
uv:curl -LsSf https://astral.sh/uv/install.sh | shThen restart your terminal to make
uvaccessible. - Create a project:
uv init quickstart && cd quickstart - Create and start a virtual environment:
uv venv && source .venv/bin/activate - Install the
modularPython package:- Nightly
- Stable
uv pip install modular \ --index-url https://dl.modular.com/public/nightly/python/simple/ \ --prerelease allowuv pip install modular \ --extra-index-url https://modular.gateway.scarf.sh/simple/
- Create a project folder:
mkdir quickstart && cd quickstart - Create and activate a virtual environment:
python3 -m venv .venv/quickstart \ && source .venv/quickstart/bin/activate - Install the
modularPython package:- Nightly
- Stable
pip install --pre modular \ --index-url https://dl.modular.com/public/nightly/python/simple/pip install modular \ --extra-index-url https://modular.gateway.scarf.sh/simple/
- If you don't have it, install conda. A common choice is with
brew:brew install miniconda - Initialize
condafor shell interaction:conda initIf you're on a Mac, instead use:
conda init zshThen restart your terminal for the changes to take effect.
- Create a project:
conda create -n quickstart - Start the virtual environment:
conda activate quickstart - Install the
modularconda package:- Nightly
- Stable
conda install -c conda-forge -c https://conda.modular.com/max-nightly/ modularconda install -c conda-forge -c https://conda.modular.com/max/ modular
Start a model endpoint
Now you'll serve an LLM from a local endpoint using max serve.
First, pick whether you want to perform text-to-text inference or image-to-text (multimodal) inference, and then select a model size. We've included a small number of model options to keep it simple, but you can explore more models in our model repository.
- Text to text
- Image to text
Select a model to change the code below:
Google's Gemma 3 models are multimodal, but MAX currently supports text input only for Gemma 3. It comes in many sizes, but they all require a compatible GPU.
Start the endpoint with the max CLI:
-
Add your HF Access Token as an environment variable:
export HF_TOKEN="hf_..."
- Agree to the Gemma 3 license.
-
Start the endpoint:
max serve --model google/gemma-3-27b-it
Select a model to change the code below:
OpenGVLab's multimodal InternVL3 models come in many sizes, but they all require a compatible GPU. They aren't gated on Hugging Face, so you don't need to provide a Hugging Face access token to start the endpoint.
Start the endpoint with the max CLI:
max serve --model OpenGVLab/InternVL3-14B-Instruct --trust-remote-codeIt will take some time to download the model, compile it, and start the server. While that's working, you can get started on the next step.
Run inference with the endpoint
Open a new terminal and send an inference request using the openai Python
API:
-
Navigate to the project you created above and then install the
openaipackage:- pixi
- uv
- pip
- conda
pixi add openaiuv add openaipip install openaiconda install -c conda-forge openai -
Activate the virtual environment:
- pixi
- uv
- pip
- conda
pixi shellsource .venv/bin/activatesource .venv/quickstart/bin/activateconda initOr if you're on a Mac, use:
conda init zsh -
Create a new file that sends an inference request:
generate-text.pyfrom openai import OpenAI client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY") completion = client.chat.completions.create( model="google/gemma-3-27b-it", messages=[ { "role": "user", "content": "Who won the world series in 2020?" }, ], ) print(completion.choices[0].message.content)Notice that the
OpenAIAPI requires theapi_keyargument, but you don't need that with MAX. -
Wait until the model server is ready—when it is, you'll see this message in your first terminal:
🚀 Server ready on http://0.0.0.0:8000 (Press CTRL+C to quit)Then run the Python script from your second terminal, and you should see results like this (your results may vary, especially for different model sizes):
python generate-text.pyThe **Los Angeles Dodgers** won the World Series in 2020! They defeated the Tampa Bay Rays 4 games to 2. It was their first World Series title since 1988.
-
Navigate to the project you created above and then install the
openaipackage:- pixi
- uv
- pip
- conda
pixi add openaiuv add openaipip install openaiconda install -c conda-forge openai -
Activate the virtual environment:
- pixi
- uv
- pip
- conda
pixi shellsource .venv/bin/activatesource .venv/quickstart/bin/activateconda initOr if you're on a Mac, use:
conda init zsh -
Create a new file that sends an inference request:
generate-image-caption.pyfrom openai import OpenAI client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY") completion = client.chat.completions.create( model="OpenGVLab/InternVL3-14B-Instruct", messages=[ { "role": "user", "content": [ { "type": "text", "text": "Write a caption for this image" }, { "type": "image_url", "image_url": { "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg" } } ] } ], max_tokens=300 ) print(completion.choices[0].message.content)Notice that the
OpenAIAPI requires theapi_keyargument, but you don't need that with MAX. -
Wait until the model server is ready—when it is, you'll see this message in your first terminal:
🚀 Server ready on http://0.0.0.0:8000 (Press CTRL+C to quit)Then run the Python script from your second terminal, and you should see results like this (your results will always be different):
python generate-image-caption.pyIn a charming English countryside setting, Mr. Bun, dressed elegantly in a tweed outfit, stands proudly on a dirt path, surrounded by lush greenery and blooming wildflowers.
Benchmark the endpoint
While still in your second terminal, run the following command to benchmark your endpoint:
max benchmark \
--model google/gemma-3-27b-it \
--backend modular \
--endpoint /v1/chat/completions \
--dataset-name sonnet \
--num-prompts 500 \
--sonnet-input-len 550 \
--output-lengths 256 \
--sonnet-prefix-len 200max benchmark \
--model OpenGVLab/InternVL3-14B-Instruct \
--backend modular \
--endpoint /v1/chat/completions \
--dataset-name random \
--num-prompts 500 \
--random-input-len 40 \
--random-output-len 150 \
--random-image-size 512,512 \
--random-coefficient-of-variation 0.1,0.6When it's done, you'll see the results printed to the terminal.
If you want to save the results, add the --save-result flag and it'll save a
JSON file in the local directory. You can specify the file name with
--result-filename and change the directory with --result-dir. For example:
max benchmark \
...
--save-result \
--result-filename "quickstart-benchmark.json" \
--result-dir "results"The benchmark options above are just a starting point. When you want to
save your own benchmark configurations, you can define them in a YAML file
and pass it to the --config-file option. For example configurations, see our
benchmark config files on
GitHub.
For more details about the tool, including other datasets and configuration
options, see the max benchmark documentation.
Next steps
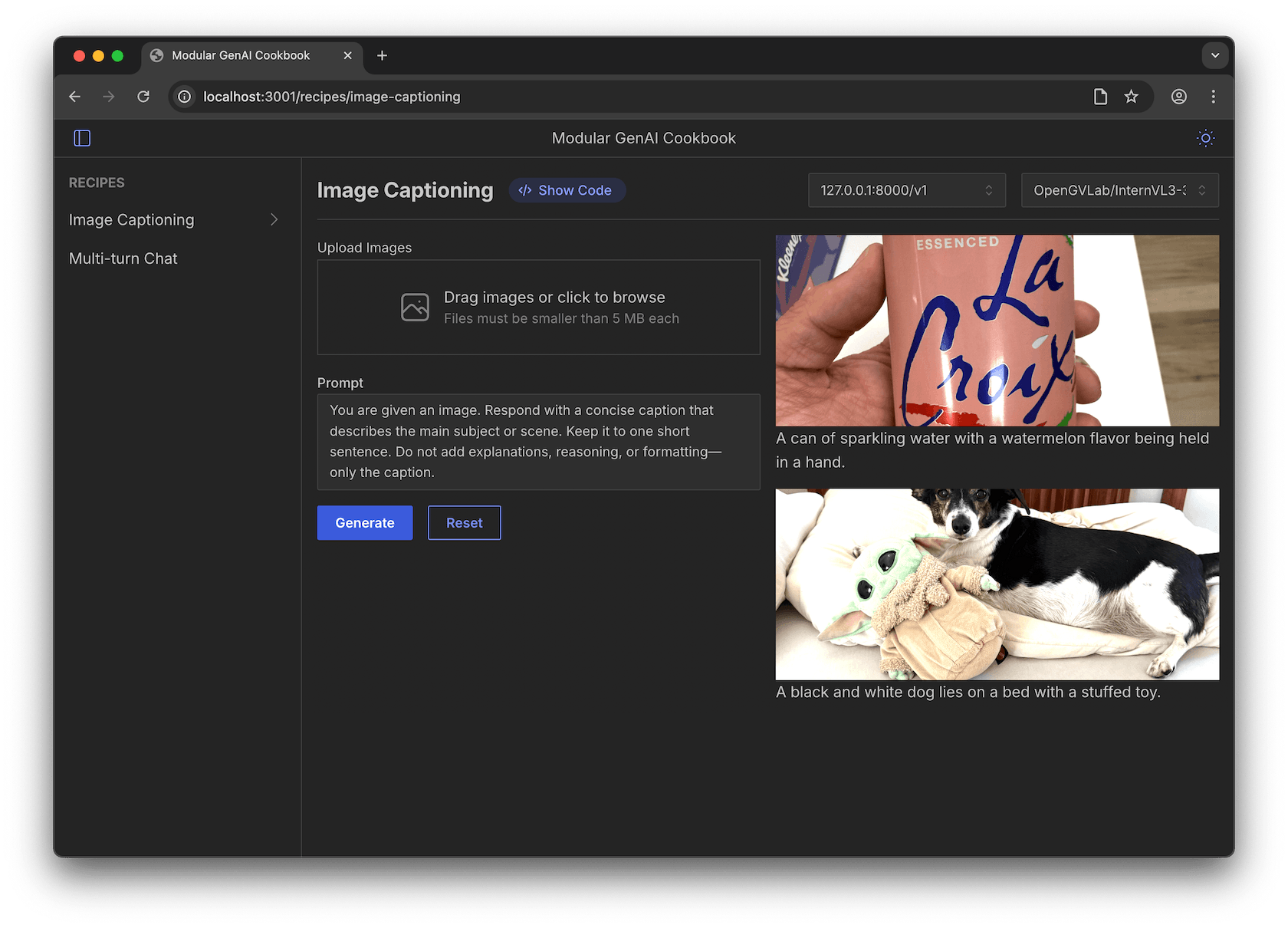
Now that you have an endpoint, connect to it with our GenAI Cookbook—an open-source project for building React-based interfaces for any model endpoint. Just clone the repo, run it with npm, and pick a recipe such as a chat interface, a drag-and-drop image caption tool, or build your own.
To get started, see the project README.
Stay in touch
If you have any issues or want to share your experience, reach out on the Modular Forum or Discord.
Get the latest updates
Stay up to date with announcements and releases. We're moving fast over here.
Talk to an AI Expert
Connect with our product experts to explore how we can help you deploy and serve AI models with high performance, scalability, and cost-efficiency.
Was this page helpful?
Thank you! We'll create more content like this.
Thank you for helping us improve!