MAX Engine
The foundation of the MAX platform is its ability to accelerate AI models with our next-generation graph compiler and runtime called MAX Engine. Using our Python API, it takes just a few lines of code to accelerate a PyTorch model or execute a native MAX model:
- Create an
InferenceSessionwith themax.engineAPI. - Load the model into the
InferenceSession. - Pass your input into the loaded model.
Or, if you want to build a client-server application, you can instead use our ready-to-deploy container that wraps MAX Engine in a serving library called MAX Serve. All you need to do is specify the LLM you want to run and deploy it. Then you can send inference requests to the server's OpenAI REST endpoint, and it returns the results from MAX Engine.
How it works
Whether you use the Python API to run inference within your app or use the REST API hosted by MAX Serve, MAX Engine is the runtime that executes your model.
When you load your model into MAX Engine, the graph compiler inspects, analyzes, and optimizes the model's graph using next-generation compiler technologies. It performs compilation on the same hardware where it will execute ("just in time" or JIT compilation), which allows MAX Engine to optimize the model for each machine, using hardware-specific capabilities.
MAX Engine is particularly powerful because we built it with an all-new compiler stack, using high-performance GPU kernels written in Mojo and without vendor-specific hardware libraries. This enables us to quickly scale MAX Engine across a wide range of CPUs and GPUs, and deliver incredible performance on a wide range of hardware.
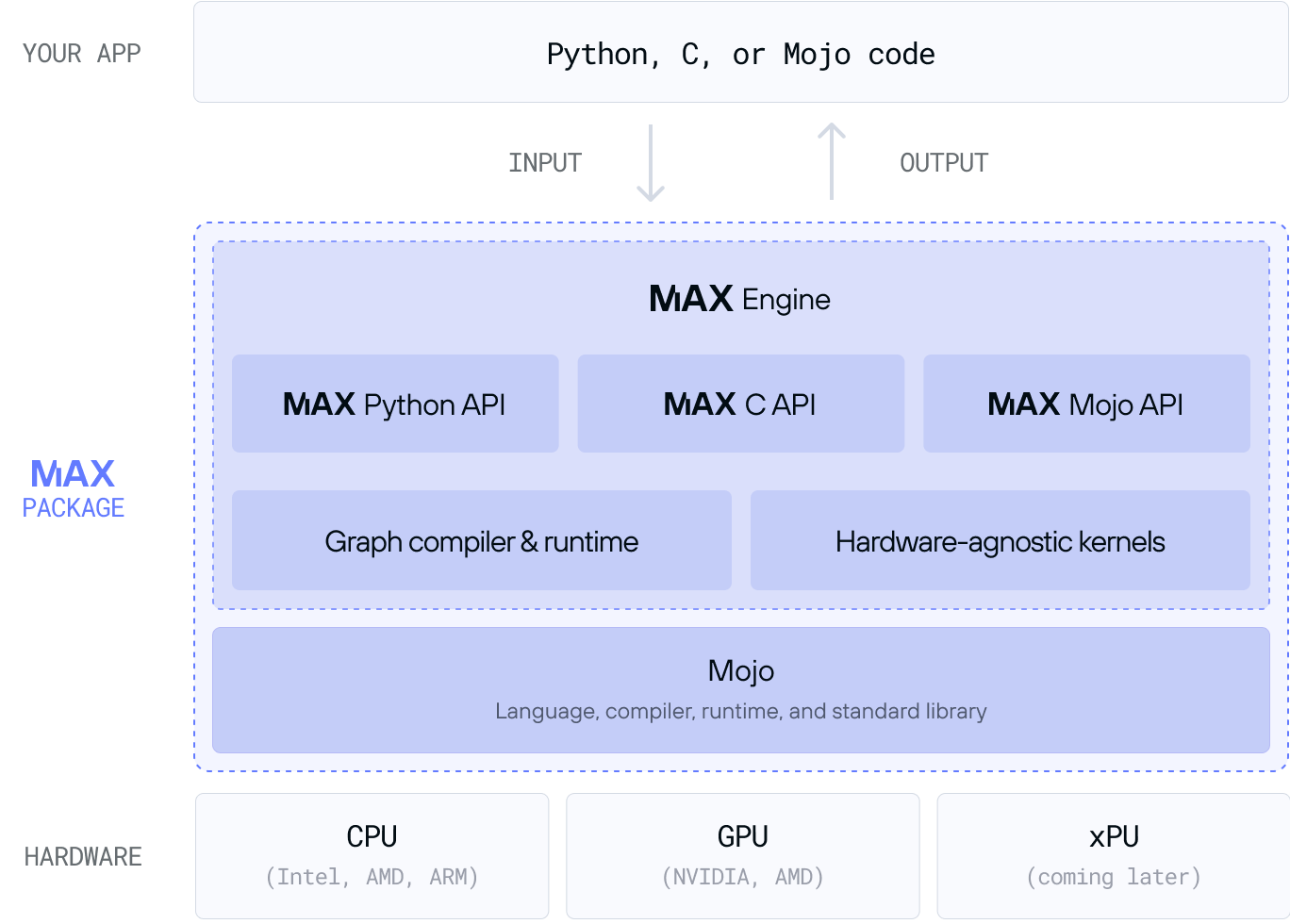
But MAX is much more than just the MAX Engine compiler and runtime—it's a complete toolkit for AI developers and deployers. MAX also includes a Python API to build and optimize GenAI models, called MAX Graph, and the serving library that we've already described, called MAX Serve.
And in a future release, you too will be able to write GPU kernels that are hardware-agnostic, using Mojo.
Get started

Was this page helpful?
Thank you! We'll create more content like this.
Thank you for helping us improve!