MAX Serve
MAX simplifies the process to own your AI endpoint with a ready-to-deploy inference server called MAX Serve. It's a Python-based serving layer that executes large language models (LLMs) and provides an OpenAI REST endpoint, both locally and in the cloud.
We designed MAX Serve to deliver consistent and reliable performance at scale for LLMs using complex batching and scheduling techniques. It supports native MAX models (models built with MAX Graph) when you want a high-performance GenAI deployment, and off-the-shelf PyTorch LLMs from HuggingFace when you want to explore and experiment.
How it works
We built MAX Serve as a Python library that can run a local endpoint with a
magic CLI command, and deploy to the cloud with our MAX
container. In either case, it provides an OpenAI REST endpoint
to handle incoming requests for your LLM, and a Prometheus-formatted metrics
endpoint to track your model's performance.
MAX Serve provides a low-latency service using a combination of performance-focused designs, including a multi-process HTTP/model worker architecture (maximum CPU core utilization), continuous heterogeneous batching (no waiting to fill a batch size), and multi-step scheduling (parallelize more inference steps for better GPU utilization).
Under the hood, MAX Serve wraps MAX Engine, which is our next-generation graph compiler and runtime that accelerates native MAX models and PyTorch models on both CPUs and GPUs.
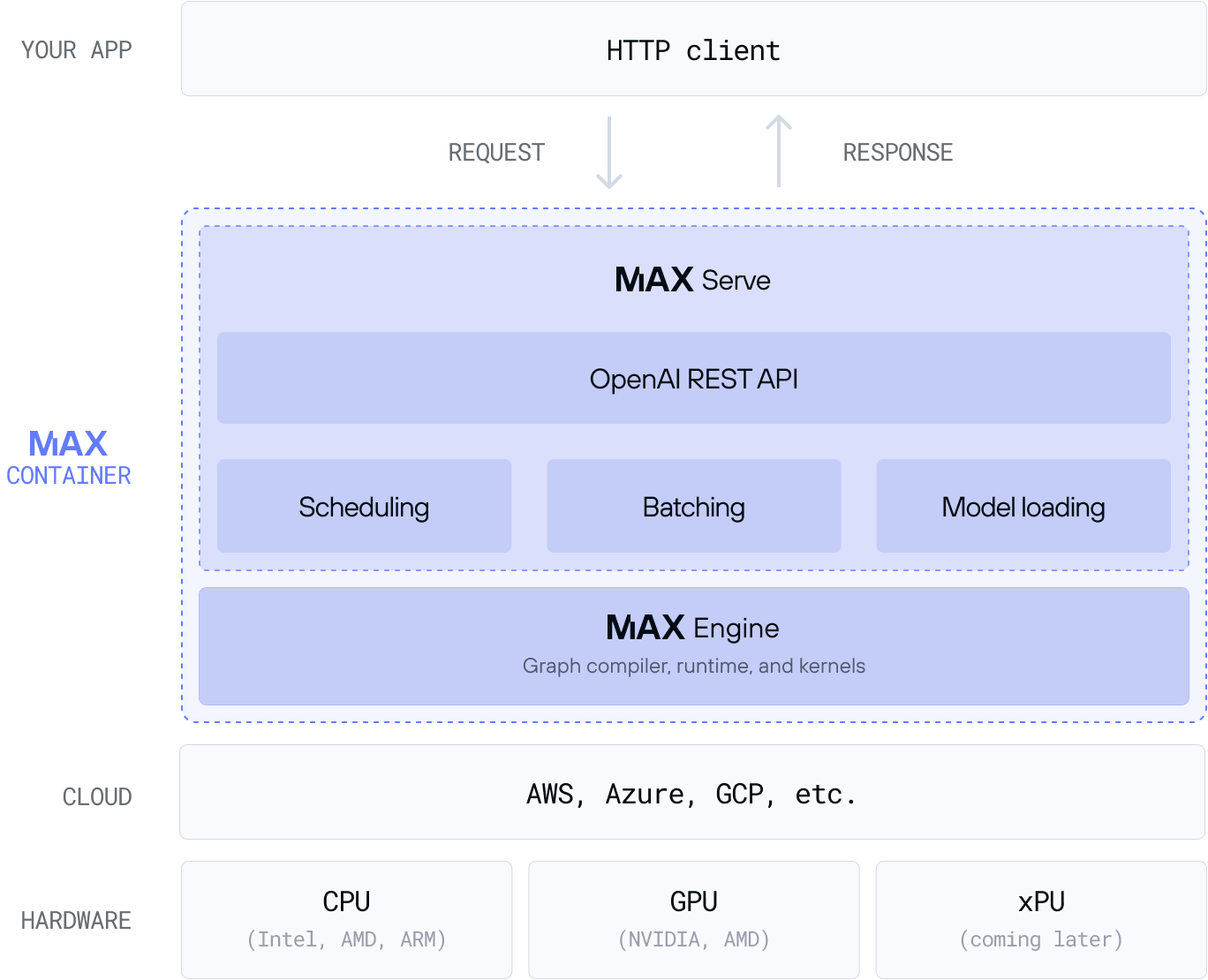
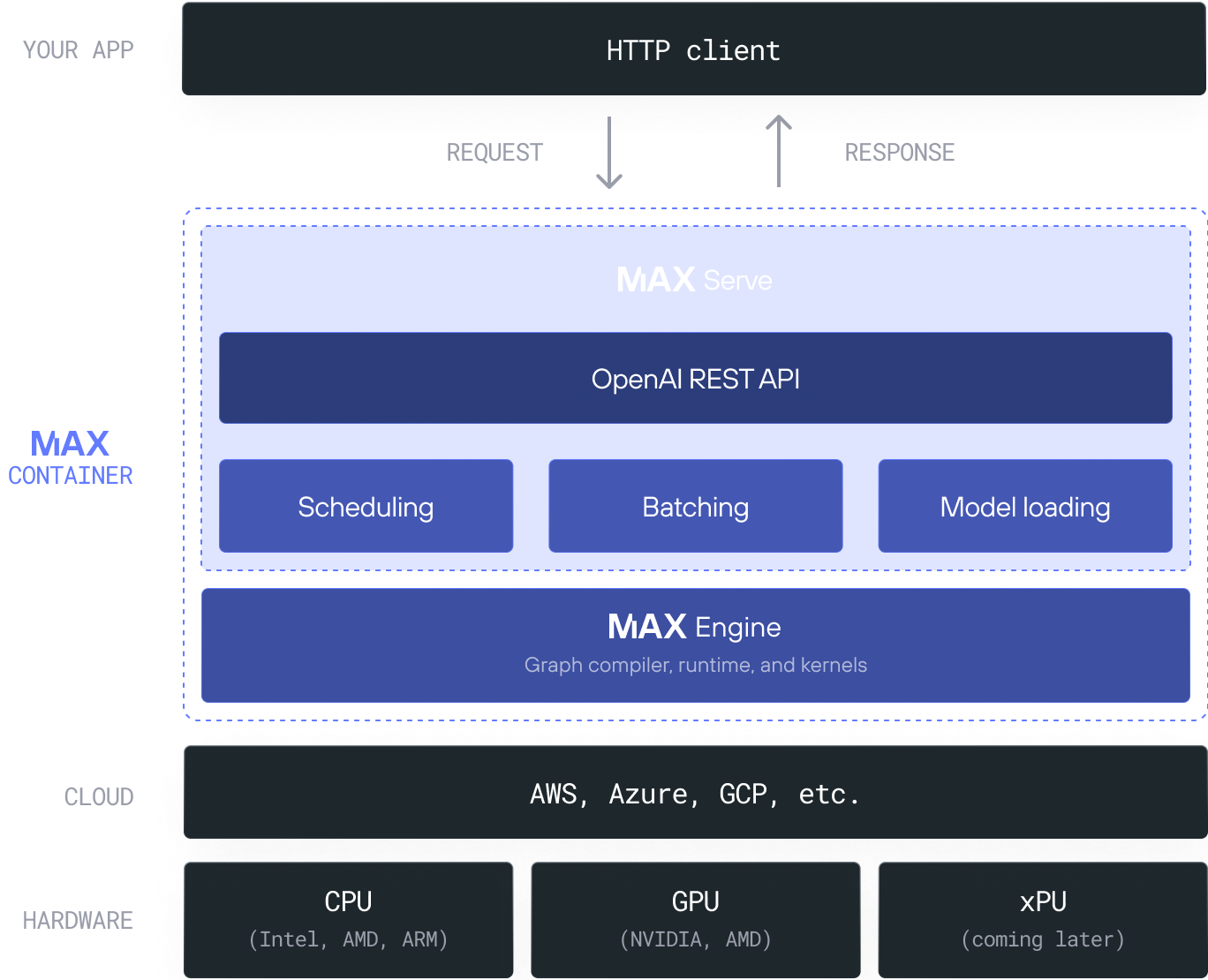
The MAX container illustrated in figure 1 is pre-configured for compatibility with several different NVIDIA GPU architectures (and AMD GPU support is in the works). All you need to do is specify the LLM you want to serve. You can specify the name of a PyTorch LLM from Hugging Face or, for the best performance, select one of our LLMs built with the MAX Graph API (available on GitHub).
You can also start a MAX Serve endpoint without the MAX container, using a
magic CLI command that executes the same MAX Serve program as the MAX
container. To try it yourself today with one of the following tutorials.
Get started

Was this page helpful?
Thank you! We'll create more content like this.
Thank you for helping us improve!